
“What we’ve underestimated is the degree to which human beliefs, values, and even personalities are embedded in everything we do, everything we build, including software.”
Based on a talk given at the NASEM Roundtable Adopting Open Science Practices: Researcher Perspectives on Incentives and Disincentives | Kristen Ratan | September 20, 2019
Infrastructure is the street we walk on, the trains we take, the airports we fly in and out of. It’s also the servers we use, the standards that keep us safe, and the software embedded in our cars, our refrigerators, our phones and more. So far we’ve taken an innovative but hap-hazard approach to our technological infrastructure. We expect smart people to build things and we don’t ask a lot of questions about how and why they do.
“There are benefits to open and risks to closed infrastructure”
I’m a fan of open infrastructure over proprietary solutions. I’m also in favor of communities having some say in how their infrastructure is built and run, the types of metrics being collected, and how these are used. I think that this is particularly important when we are talking about some of the world’s most precious information and people – in the world of research and education.
With closed, companies can buy and sell your infrastructure at any time. Closed infrastructure often owns the data that it contains and generates. This means that data about your content, its authors, its readers, your data, your research pursuits, your students, can all be bought and sold. With open access, we are trying to reverse having given away the rights to years of research content. Let’s not do the same with all of the data of research, scholarship and education.



Finally, Infrastructure is what we make it. We tend to think about infrastructure as a thing (or set of things) but these things house processes and when we want to change behaviors we need the processes that are written into infrastructure to match our goals. And probably most concerning, they can codify the wrong values – build things in ways that hurt. Closed infrastructure can take your open access articles, preprints, data and lock them up in a new way so that you may have trouble getting them out easily, you may not know how they are being used, and you’ve lost the data about the content.
There is a bigger game afoot than open source
I’m sure most of you have read the SPARC report on infrastructure – it analyzes the current landscape including what the largest corporate players are doing, their strategies and, more importantly, their future revenue streams. Sparc believes, and I agree, that the needs of the community are not being well-served by the existing scholarly communication infrastructure, which is dominated by vendors whose missions and values often run counter to those of the community. More alarmingly, large publishers and information corporations are moving to a data analytics business model – they are expanding beyond journals and textbooks to include research assessment systems, productivity tools, online learning management systems –infrastructure for all aspects of the university.


That means that they now have data about faculty and students, research outputs before publication, and more. This type of data has competitive value orders of magnitude greater than the publishing business.The Sparc report recommends establishing detailed data policies and mechanisms for ensuring compliance. Such as maintaining ownership of data. Express these in the contracts with commercial vendors are not covered by non-disclosure agreements (i.e. open procurement), that algorithms are transparent, and more. Further, you should ensure that data cannot be not sold to third parties or given to government agencies without your permission
Ubiquitous problem
Google’s terms of service say “When you upload, submit, store, send or receive content to or through Google Drive, you give Google a worldwide license to use, host, store, reproduce, modify, create derivative works (such as those resulting from translations, adaptations or other changes we make so that your content works better with our services), communicate, publish, publicly perform, publicly display and distribute such content.”
At any time, Google can mine, publish, or apparently do an interpretive dance based on the content of your google docs.

In 2016, Amazon.com, Inc. used software to determine the parts of the United States to which it would offer free same-day delivery. The algorithms made decisions that prevented minority neighborhoods from participating in the program, often when every surrounding neighborhood was included. They have also had to deal with discriminatory HR algorithms and racial bias in facial recognition software.
The airline systems that overcharged people who were trying to escape from the Hurricane Irma. Their algorithms look for demand in buying patterns and automatically raise prices.
These two can be passed off as mistakes, unintended consequences, but with the Volkswagen emissions scandal, software was deliberately designed to beat the tests. This was a direct result of a misalignment of the company’s stated corporate values and the realization of its values in its software systems. Software installed in the electronic control module (ECM) would detect when the car was undergoing emissions testing and use a different ‘map’ that would reduce emissions.
In all three cases, the values of the company, which were to sell more, earn more, were not shared by its consumers or the general public, which expected them to have at least some degree of conscience.
Of course, this wall of shame would not be complete without Facebook. They have the honor of having been used to undermine democracy and change history.
Facebooks Values are to: Make money, Build marketshare. They do this through targeted advertising, as do many companies. As a consequence, they’ve made billions. As an unintended consequence, their platform has been subverted for political gain. The same software structure that allows people to share cat photos, allows for sharing of fake news. The same algorithms track everything about you and your friends to push ads and content at you turns out to be brilliant at spreading fake news.
Facebook is trying to fix this with new algorithms, fake news detectors, etc. But none of these measures change the values inherent in a platform designed to drive behaviors for profit.
The metrics measure friends and likes, but imagine if it were driven by different values, and started measuring how often you shared fake news and then posted this to your network.
We Encode Our Values, beliefs and personalities
What we’ve underestimated is the degree to which human beliefs, values, and even personalities are embedded in everything we do, everything we build, including software. Frequently we don’t even realize that we’re doing this. Facebook’s values will always be profit, market share, growth. This has been baked solidity into its DNA, it’s code. It is in its nature.

And while this has always been so, but the problem has mushroomed, surfacing in all of these places that we didn’t expect.
The values come from those who create it. Intentionally or unintentionally, this leads to different types of bias. Approximately 80% of all software engineers in the US are male. And 70% are white. Most commercial software is written to support profit and growth. If we want fairness, we have to staff for it and infuse our values in from the start.
Because software is everywhere and getting smarter every day, we must work intentionally to ensure fairness in software. This is impacting the criminal justice system, military technologies, healthcare, and education, among others.
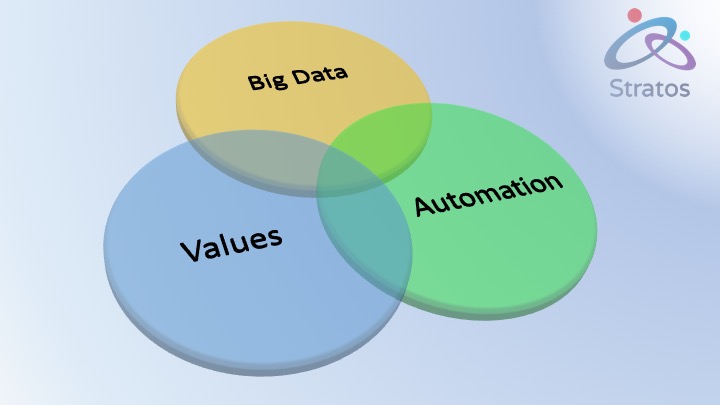
The problem is mushrooming due to the confluence of bigger and bigger data, more automation through technology, and, although we didn’t really think this through, values. If you aren’t consciously putting something in this blue circle, the default value for the software builders will sit here.
Help is on the way
The good news is that people are working on this. It’s possible now to conduct fairness testing of software for discrimination. This is something that we can bake into infrastructure projects from the beginning. And do ongoing tests of infrastructure to see how they fair over time. Some examples of what’s being done:
- Galhotra et al: Built Themis to detect discrimination. We must try to ensure fairness in software.
- And the AI Fairness 360 toolkit (AIF360) is an open source software toolkit that can help detect and remove bias in machine learning models. From IBM.
- DeepXplore is another testing option, so we can use these types of tools to find out when and where bias and discrimination are occurring.
Also, people are working on new software development methodologies that bring ethics and fairness into the process early on, bring new stakeholder voices in.


Know your values. Code your values
There is a direct line from values to policies to things like guidelines, methodologies, to what is being measured and how. And all of this must be thought through before and during infrastructure implementation

Some takeaways:
· Insist on open source, community-owned infrastructure where data and values matter
· Adopt Sparc’s policy recommendations and review these Principles for Open Scholarly Infrastructures (Bilder, Lin, Neylon)
· Insist on a values-based software development process, testing for discrimination
Consider your values:
· If you value diversity, learn who’s on the teams that build your stuff.
· If you value open, make it open source, open standards part of your RFPs and contracts.
· If you value equity, test for discrimination, fix it, test it again, bring in your community and experts.
· If you value transparency, use ethics-driven open source software development methodologies and engage your stakeholders
· If you value your time, work together and support efforts already underway, such as Invest in Open Infrastructure