Thanks in large part to the OSTP Nelson memo, the availability of research data is getting a level of attention that many of us think is long overdue. ‘Data sharing,’ as it’s commonly known, is a bit of a misnomer that belies both the work that goes into meeting even minimum requirements and the impact it has when it is made truly reusable.
There is no shortage of confusion on what data sharing really means in practice and though there are many useful resources available, case studies are especially useful for modeling the ways forward.
Not as simple as it sounds
Disciplinary norms and differences as well as varying institutional resources available to researchers make the data sharing landscape highly variable. Still, there are some common challenges to reliable and responsible data sharing, including:
- Data curation: redacting sensitive data such as personally identifiable information is a well-understood example of the need for curation but even basic ‘clean up’ of data files can be time-intensive and produce data of varying quality without training, expert guidance and best practices to guide busy researchers
- Ensuring adequate metadata: a challenging problem even for published papers despite a long history of scholarly publishing, systems and norms have not yet caught up to the need for consistent, quality metadata for shared research data, to the detriment of discoverability (and researchers’ time)
- Finding appropriate repositories with PIDs: we may not yet be spoiled for choice but the array of existing institutional, subject-specific and general repositories poses a challenge for guiding busy researchers to the most appropriate destination(s) for their data
- Moving from posting datasets to interoperable, FAIR sharing: posting may technically be sharing but interoperability is key for reuse and evaluating FAIR-ness is still very much an emerging set of practices
- Fueling data lakes and hubs instead of data graveyards: data will naturally collect in places throughout the current landscape (for example for limited-term projects) but sustained, structured resources require infrastructure that interlink data (and people)
- Tying code to data for containerized reuse: services such as tools for reuse including the code used to create or manage the data being shared needs to be linked in a structured way
- Redistributing credit to track and rewards all outputs and activities: the effort that goes into providing this fundamental information is unevenly incentivized and recognized (if at all), let alone rewarded.
Leading examples
Fortunately, there are case studies from which we can learn about handling such challenges and maximizing the benefits of open, interconnected research data and the people behind it.
In cancer research, cBioPortal for genomics and the NIH’s Genomics Data Commons (GDC) Data Portal are useful examples of sharing in the more collaborative data lake or hub approach, rather than the more isolated graveyard model.
Neurodata Without Borders has an explicit aim of standardizing neuroscience data at scale.
It is not surprising that well-funded and data-intensive areas like these may be among the first out of the gate with such robust approaches. Still, as is so often the case, coordination and collaboration -people working together- is as much a contributor to establishing such resources as the technology and funding behind them.
Recognition and impact
Ultimately, understanding the return on investment for all of this work is of interest, directly or indirectly, to stakeholders across the research community, certainly those that fund and conduct the work being shared. The baseline may be that the data are available and linked to ‘the paper’ (preprint, article, etc.) but beyond that, there are a number of criteria for both evaluating and incentivizing this sharing.
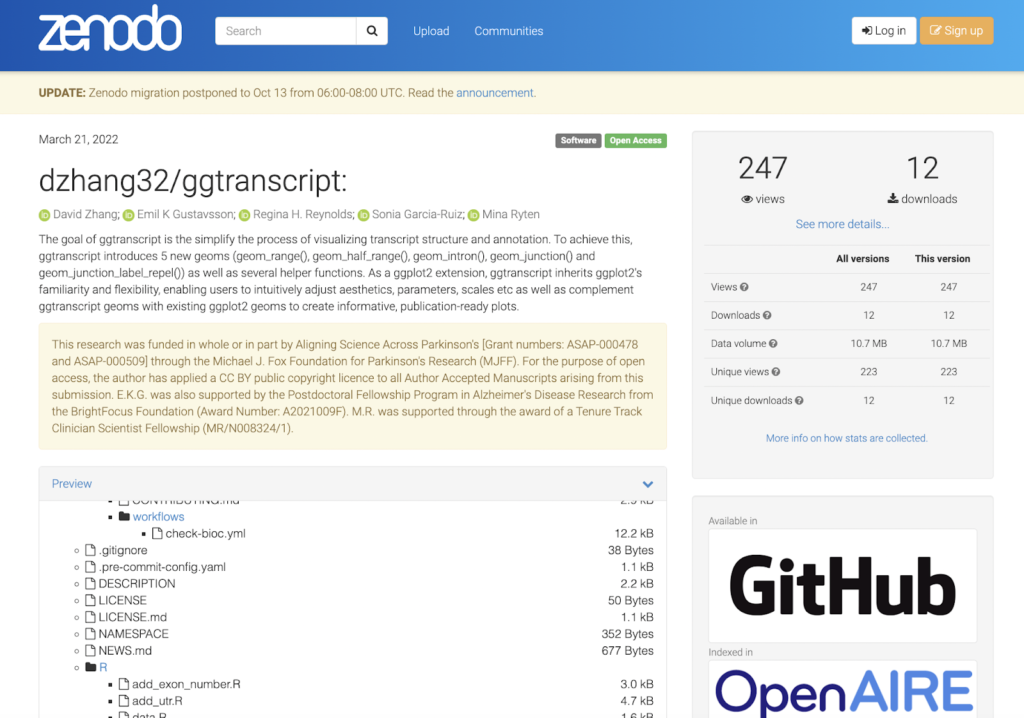
Aligning Science Across Parkinson’s (ASAP) is an open science funding initiative that has built open practices into its entire workflow, including policies that touch on credit and assessment. They use a managed network hub approach to sharing outputs including protocols, datasets, animal models, cell lines and other output types alongside (and linked with) articles.
As expected, they do have an Open Access (OA) publishing policy but their focus is much less on traditional indicators of credit such as Journal Impact Factor (JIF) and much more on emerging indicators, including openness and timeliness of a range of shared outputs, their influence on policy and collaboration and reuse, as shown in this example on Zenodo:
Building on and up
Despite the significant challenges to robust data sharing, it is important to highlight that a great deal of infrastructure and community is already in place to support policies and practices to make the most of sharing curated, interlinked and interoperable research data.
Examples of community resources and initiatives are highlighted through ICOR (Incentivizing Collaborative and Open Research). We would love to share your work on this important topic so if you have a story to tell about data sharing or are looking for guidance on where to go with your ideas and questions, please get in touch.